搜索引擎:Spider抓取系统的基本框架
来源:上海网站制作 点击:次 日期:2015-05-07
互联网信息爆发式增长,关注上海网站建设的大家都想知道如何有效的获取并利用这些信息是搜索引擎工作中的首要环节。协策网络(上海网站建设)在这里为大家进行简单的解答:
数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做“spider”。例如我们常用的几家通用搜索引擎蜘蛛被称为:Baiduspdier、Googlebot、Sogou Web Spider等。
Spider抓取系统是搜索引擎数据来源的重要保证,如果把web理解为一个有向图,那么spider的工作过程可以认为是对这个有向图的遍历。从一些重要的种子 URL开始,通过页面上的超链接关系,不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型spider系统,因为每时 每刻都存在网页被修改、删除或出现新的超链接的可能,因此,还要对spider过去抓取过的页面保持更新,维护一个URL库和页面库。
下图为spider抓取系统的基本框架图,其中包括链接存储系统、链接选取系统、dns解析服务系统、抓取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。Baiduspider即是通过这种系统的通力合作完成对互联网页面的抓取工作。
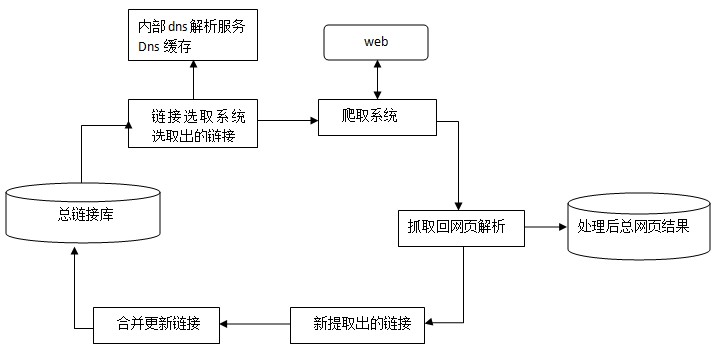
以上【 搜索引擎:Spider抓取系统的基本框架 】的内容由协策网络公司(http://www.580plan.com/)为您提供,本文网址: ,转载请注明出处,更多有关上海网站建设,网站优化、微信网站制作(微官网)、手机app开发、商业摄影、企业宣传片制作、400电话、电商代运营等互联网应用服务都可以联系我们。热线:51085186或致电18018609689王经理。
协策网络公司每天都会不定时更新有关网站建设以及网络营销推广的文章,希望对您有用。
